Build Your First RAG System.
A self-paced crash course for data scientists who want to build with RAG, not just talk about it. Three hands-on projects walk you through extraction, retrieval, and evaluation end to end.

Built by Andres Vourakis
Senior Data Scientist • 8+ years experience
RAG Crash Course
One-time payment. No recurring fees.
Most RAG content is either too shallow or built for software engineers.
Blog posts give you a vague picture. Production-grade tutorials drown you in infrastructure you do not need yet. Almost none of them teach you how to know whether your RAG system actually works.
This course is built for that middle. Enough theory to make the right calls. Three hands-on projects you can extend.
What You'll Learn
Six lessons across three arcs: extraction, retrieval, and evaluation. Three of them include a hands-on project you can extend.
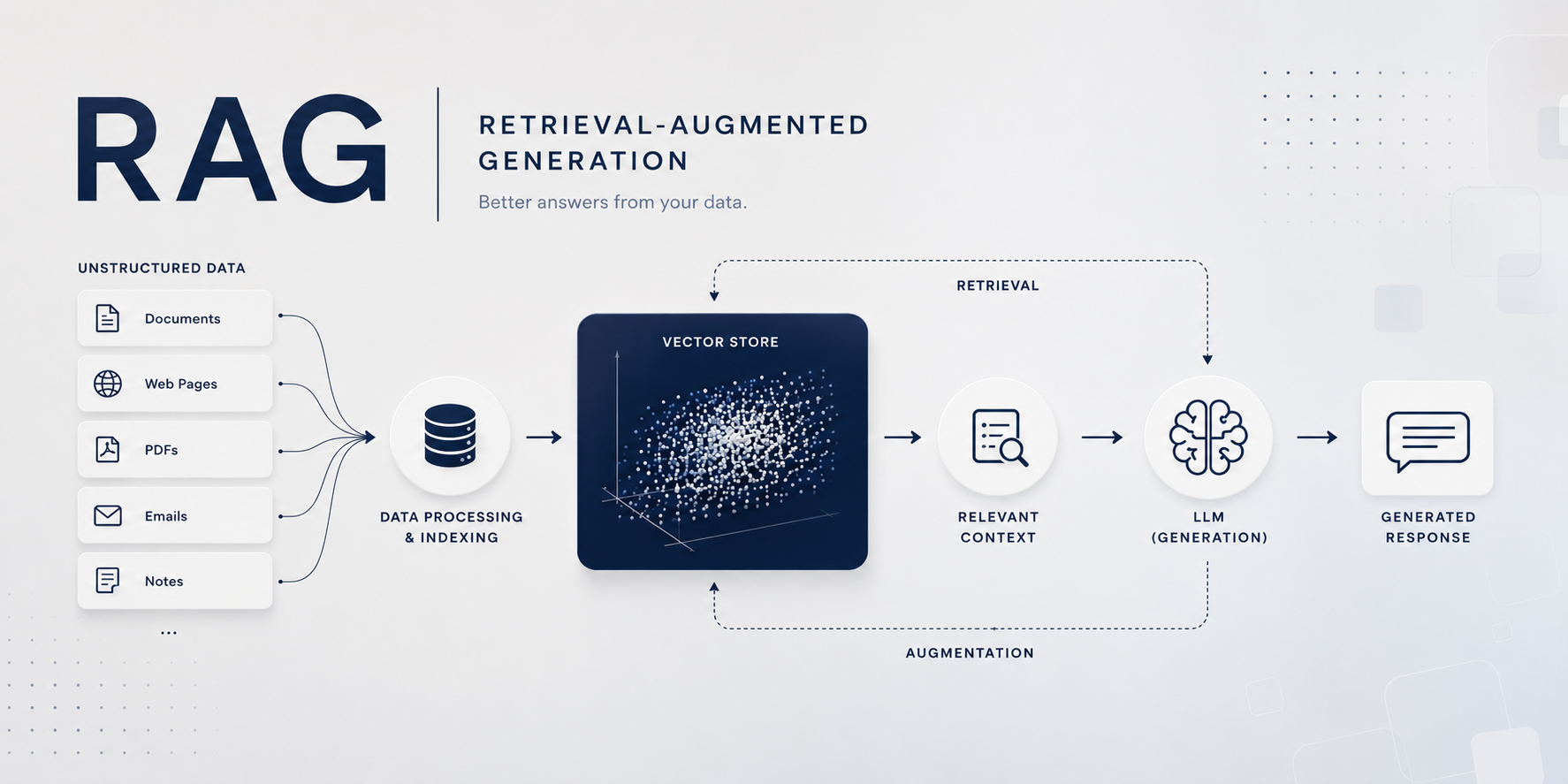
How RAG actually works
The three phases of the pipeline (ingestion, retrieval, generation) and what "grounded answers with citations" really means. Framed for a data scientist: SQL is retrieval over rows, RAG is retrieval over text.
When not to reach for RAG
Three filters for whether RAG is the right tool at all. When the prompt is enough, when web search beats your own pipeline, when SQL or a semantic layer is the right answer, and where MCP servers fit in.
Document extraction
Bad extraction is the silent killer of RAG. The three approaches (naive text, classical OCR, VLM-based parsing) and the modern toolset: PyMuPDF, Docling, LlamaParse, or a VLM via API.
Chunking and embeddings
Fixed-size and structure-aware chunking, picking an embedding model, and the hidden ways context gets lost. Plus where the field is heading: late chunking and hybrid search.
Build the pipeline with pgvector
Query embedding, top-K retrieval, prompt assembly, generation. You ship a working ask_docs(question) function over a real corpus, no dedicated vector database required.
Evaluation: the part most courses skip
Retrieval eval vs generation eval. Ground truth datasets and the pitfalls of building one. Run precision@k and recall@k on your own pipeline and use the metrics to iterate on chunking, embeddings, or prompts.
Format
- Self-paced video lessons
Watch in any order, on your schedule. No live sessions to miss.
- 6 to 10 hours total
Designed to be finishable in a focused weekend. Watch faster if you already know parts of the stack.
- Three hands-on projects
You build PDF extraction, a working RAG pipeline with pgvector, and an evaluation loop. The code is yours to keep and extend.
- Lifetime access
Pay once, keep access to all current and future updates of the course.
Who it's for
- Data scientists who want to understand RAG well enough to build with it, not just talk about it.
- Data professionals from analytics, BI, or ML backgrounds who want a clear path into applied AI.
- People who want to start learning right now, on their own schedule.
Prerequisites
You should be comfortable writing Python. No prior RAG or LLM experience required.
Ready to ship your first RAG system?
One weekend. Yours forever. $249.
One-time payment. Lifetime access.