What Is a Semantic Layer? The Foundation of Agentic Analytics

Quick answer. Agentic analytics is a category of data systems where AI agents work across the full data-to-insight loop, from preparing data to generating insights and triggering actions, autonomously or in response to questions. Conversational analytics, the "talk to your data" interfaces vendors like Omni, Looker, and dbt are pushing, is its most visible mode and one of the biggest forces behind the current semantic layer revival. The semantic layer itself is what makes either work: a shared, machine-readable definition of your business metrics that lets agents reason about your data without guessing. The Open Semantic Interchange (OSI), announced in September 2025 and backed by Snowflake, dbt Labs, Google, Cube, and others, is turning this into an industry standard.
A semantic layer is the shared, machine-readable definition layer between your raw data and the people, tools, and AI agents that consume it. It encodes what your business actually means by terms like active user, churn, or monthly recurring revenue, so every consumer of the data (dashboards, notebooks, agents) returns the same answer instead of each one quietly guessing.
This is one of those quiet shifts nobody is talking about loudly enough.
A real architectural change is underway in how data and AI fit together, and data scientists will feel it directly over the next 18 months. The industry has settled on a name for it: agentic analytics. And the semantic layer (alongside its older cousin, the ontology) is what's actually making it work under the hood.
If any of that still reads as jargon, you're in the right place. The point of this piece is to break down what is actually happening, how the pieces fit, and why a working data scientist should care.
What matters: if your job touches data and analytics in any way, this is not a topic to ignore. It's a chance to shape how the next generation of analysts will work, instead of catching up to it two years late.
Here's what we'll cover:
- What is agentic analytics?
- What is a semantic layer (and why now)?
- Where the industry is headed: the OSI promise
- How dbt, Cube, Looker, Snowflake, and Omni compare
- What the vendor pitch leaves out
- Near-term predictions
- What this means for data scientists
What is agentic analytics?
Agentic analytics is the next step in how data work gets done: AI agents that work across the full data-to-insight workflow, autonomously or semi-autonomously, toward defined business goals. They can ingest data, detect patterns, generate insights, recommend actions, and in many cases trigger those actions directly.
And no, it's not just another buzzword. It's a natural evolution of how analytics is done.
Most of the early coverage frames agentic analytics as conversational analytics, the "talk to your data" experience that tools like Omni, Looker, and dbt are putting in front of customers right now: a chat interface that interprets a question, queries the right table, and hands back an answer. That's one mode, and the most visible one. It's also where most of the customer demand is coming from, which is why it has been a major driver behind both the resurgence of the semantic layer and the push toward OSI. But the bigger shift, on the horizon, is agents that work continuously: monitoring streams, surfacing anomalies, updating forecasts, and triggering downstream workflows without waiting for someone to ask.
For years, the industry's answer to data access was self-serve analytics. The premise was simple: arm business users with dashboards and BI tools so they could explore data on their own, without having to file a ticket and wait three weeks for the data team to get to it.
It produced real wins. Features like Looker's "Explore from here" gave non-technical teams more autonomy than they'd ever had with the previous generation of static reports.
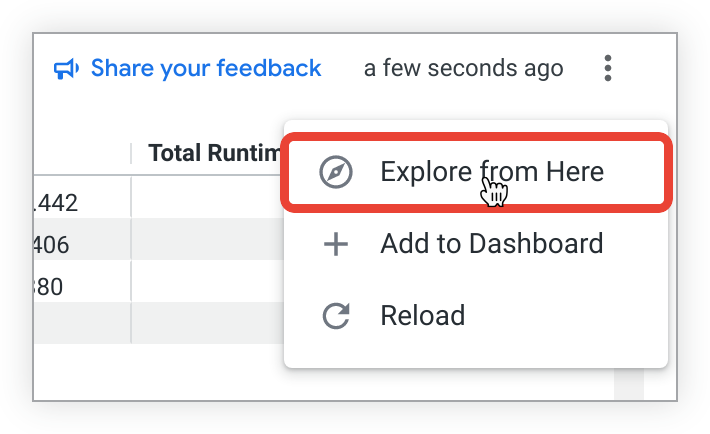
But ask anyone running a modern data team and the bottlenecks look painfully familiar:
- Every new metric definition still has to route through the data team.
- Analysts spend most of their day jumping between tools, dashboards, and Slack threads trying to reassemble context.
- Insights still arrive after the decision that needed them.
What self-serve analytics actually shipped was self-serve dashboards, not self-serve insights. There's a meaningful gap between the two, and most of us have lived in it.
That gap is where AI agents change the math.
Agents can take an analytical question, pull the right data, run the analysis, and return a result, not in days or weeks but in seconds. The interpretive layer that used to sit between the question and the answer collapses.
That's what agentic analytics captures at its core: a generation of analytics tooling where intelligent systems carry the operational load, and humans focus on direction and judgment.
But how does an AI agent actually understand your data?
Here is where the demos hide the hard part. The slick "ask any question of your data" demo doesn't show you what happens when the agent has to figure out which of the seventeen user_id columns scattered across your warehouse is the right one for this question, or what your business specifically means by "active."
The honest answer: even when an agent can technically access your data, it still has to understand it. Most agents fail there.
Your database knows what tables and columns exist. It does not know what "active user," "churn," or "retention rate" actually mean for your business. That definition lives in tribal knowledge, half-finished Notion docs, and Slack threads nobody will ever find again.
In other words: your data has structure. Your meaning doesn't.
What is a semantic layer (and why does it matter for AI agents)?
A semantic layer is the part of the modern data stack that owns what your data means. It encodes your metrics, dimensions, entity relationships, and business rules in a single machine-readable place, so every tool that touches your data, BI dashboards, notebooks, and AI agents, interprets it consistently.
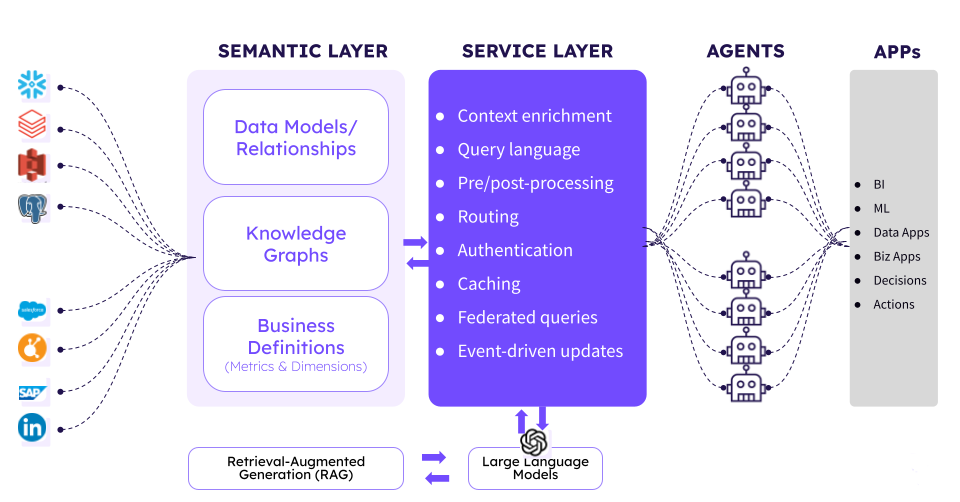
Without one, every AI agent you build will hallucinate metrics, miscount things, or quietly contradict the dashboards your team already trusts.
The data backs this up. On Spider 2.0, a text-to-SQL benchmark built from real enterprise schemas with 1,000+ columns, GPT-4o solves only 10.1% of tasks, compared with 86.6% on the older academic version. Even o1-preview only gets to 17.1%. The model didn't get worse. The schemas got real.
With a semantic layer, the agent doesn't have to guess what "daily active users" means. It looks it up and queries the right data with the right calculation, every time.
In practice, this layer often shows up as a set of YAML files containing structured definitions of your tables, metrics, and joins. Here's a generic example:
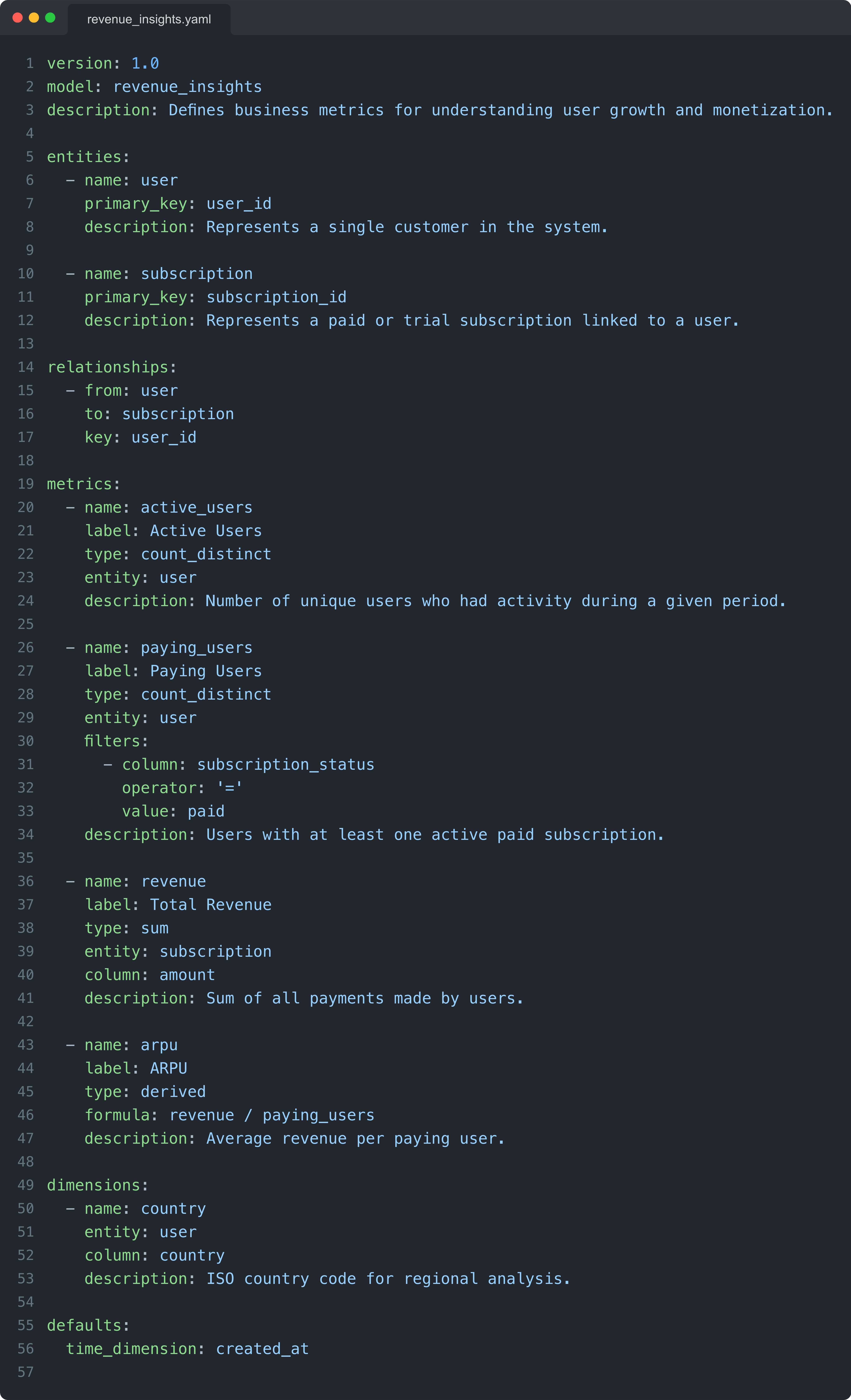
To make this concrete, here is what defining monthly_active_users looks like in dbt's MetricFlow syntax:
semantic_models:
- name: users
description: User activity facts at the daily grain. One row per user per day with activity.
model: ref('fct_user_activity')
defaults:
agg_time_dimension: activity_date
entities:
- name: user
type: primary
expr: user_id
measures:
- name: distinct_users
description: Count of distinct users with at least one activity event.
agg: count_distinct
expr: user_id
dimensions:
- name: activity_date
description: Date of the activity event, in UTC.
type: time
type_params:
time_granularity: day
metrics:
- name: monthly_active_users
description: Distinct users with at least one activity event in the trailing 30 days.
label: Monthly Active Users
type: cumulative
type_params:
measure: distinct_users
window: 30 daysThat single definition, stored once and shared everywhere, is what lets any consumer (your BI dashboards, your AI agents, your ad-hoc notebooks) return the same number for "monthly active users." No semantic layer means each consumer guesses. And different consumers guess differently.
A quick history (this isn't actually new)
A short detour, because some readers who have been in the data space for a while are already mentally yelling at me: "this concept is decades old, what are we celebrating?"
Fair.
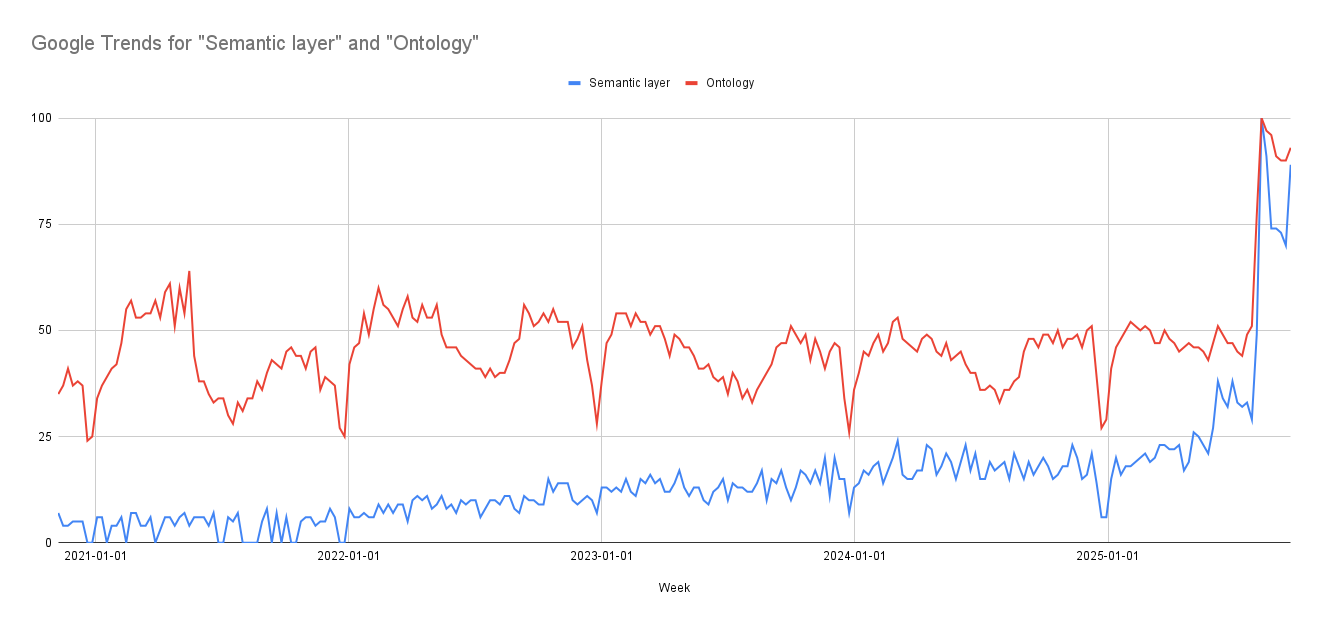
The reason semantic layers are a topic again, in 2026, is that search interest in the term spiked starting in early 2025, driven by the rise of AI agents, context-aware analytical tools, and the standardization push behind OSI (more on that in the next section).
The idea itself reaches back to the 1990s, when enterprise data warehouses introduced business views on top of raw tables, an abstraction layer that let non-technical users query data without writing SQL by hand.
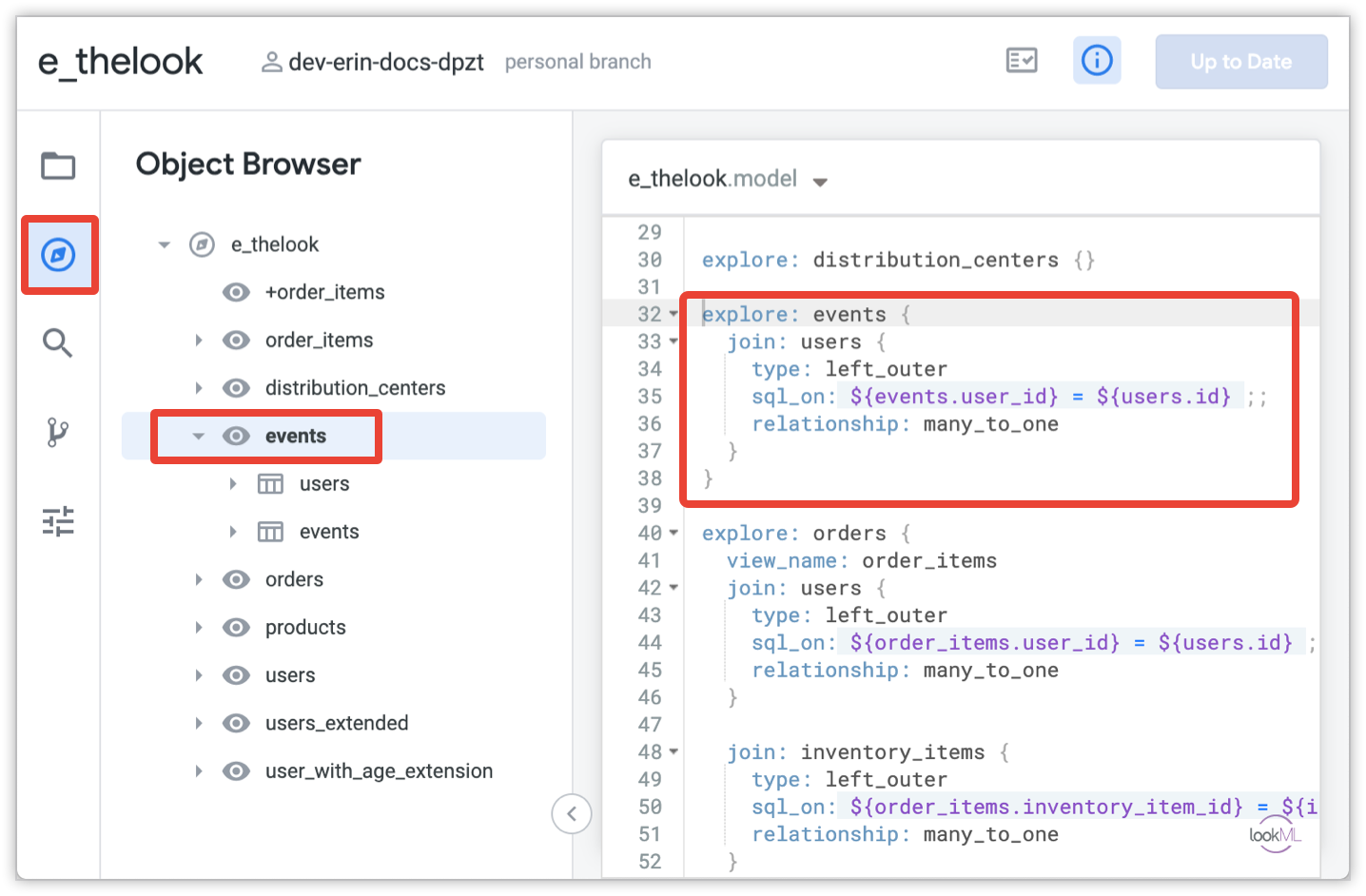
Looker is what dragged the concept into the modern stack, formalizing it as a real modeling language with LookML: a code-defined way to express metrics, joins, and relationships. That template is the one most modern semantic layers are still iterating on.
What is different in this cycle is the consumer. Semantic layers used to feed dashboards, which are read by humans. Humans are forgiving of ambiguity, they ask a clarifying question. Agents are not. A confused agent doesn't ask. It confidently returns the wrong number. The semantic layer is the difference between an AI tool that's a useful colleague and one that's a credibility liability.
What is OSI, and why does it matter?
The Open Semantic Interchange (OSI) is an open standard, announced in September 2025, for how data systems define and communicate business context. The launch coalition includes Snowflake, dbt Labs, Google, Cube, and a growing list of vendors signing on since.
History keeps making the same point: every meaningful inflection in the data stack has come from a wave of standardization. SQL standardized querying. Cloud warehouses standardized storage and compute. dbt standardized transformation. The wave we're in now standardizes the layer above transformation, the layer where business meaning lives. OSI is the bet on what that standard looks like.
This initiative reflects the industry coming together, not competing, to solve shared challenges and build a more connected, open ecosystem for all.
Snowflake

The idea is simple: instead of every platform inventing its own definition of metrics and entities, OSI provides a single shared interface that any tool or AI agent can understand.
If it works, the implications are big:
- Any AI tool (Cursor, Claude, ChatGPT, in-house agents) can plug into your company's semantic layer.
- Metric definitions become reusable across dashboards, notebooks, and agents.
- Context becomes portable, instead of something that gets lost every time you switch tools.
And it's not theoretical. dbt's MetricFlow, the engine behind the dbt Semantic Layer, is now developed and maintained as part of OSI under an Apache 2.0 license, having moved from a restrictive BSL license alongside the OSI launch. That means any tool, agent, or notebook can adopt the same metric definitions without paying a vendor for the privilege. It's the first concrete artifact of what OSI is promising, and a real signal that the industry is committing to the standard rather than just announcing it.
If keeping your business context vendor-agnostic resonates with you, this is real reason for optimism.
How do dbt, Cube, AtScale, Looker, Snowflake, and Omni compare?
The semantic layer space has consolidated around a handful of credible implementations. They share the same conceptual model (define metrics once, reuse everywhere) but differ in where they live, who they target, and what they're optimized for.
| Implementation | Where it lives | Best for | Notes |
|---|---|---|---|
| dbt Semantic Layer (MetricFlow) | Inside the dbt project, between transformations and consumers | Teams already on dbt who want metric governance in code | Apache 2.0, now developed as part of OSI |
| Cube | Independent server, integrates with dbt or runs standalone | Teams that want a dedicated layer with caching and APIs | Strong for embedded analytics and high-throughput agents |
| AtScale | Independent layer over the warehouse, vendor-neutral | Enterprise teams that want a semantic layer decoupled from any specific BI tool | Pitched explicitly as a semantic layer for AI; longer enterprise track record than most |
| Looker (LookML) | Historically tied to the Looker BI product | Teams committed to Looker as their primary BI front end | Proprietary modeling language. Google is exposing LookML semantics to external tools via Looker Modeler, and is an OSI launch partner |
| Snowflake Semantic Views (Cortex) | Native to Snowflake | Snowflake-heavy teams who want semantics co-located with the warehouse | Tightly integrated with the warehouse today. Snowflake is an OSI launch partner, so portability is on the roadmap rather than fully shipped |
| Omni | Cloud BI product with built-in semantic modeling | Teams that want BI and the semantic layer as one tool | One of the more aggressive vendors on conversational analytics |
The picture you should walk away with: most of these are converging on the same idea (one definition, many consumers), and OSI is the bet that they'll converge on the same format. Where you land depends on your existing stack. If you're on dbt, MetricFlow is the obvious starting point. If you're not, Cube and AtScale are the most-portable independent options: Cube leans developer-first and embedded use cases, AtScale leans toward larger enterprise.
What I'd avoid: picking a semantic layer because the vendor pitched you the loudest. The market is consolidating fast, and a layer tied tightly to one BI tool will hurt you the day you want to switch tools.
What the vendor pitch leaves out
Here is the part the vendor blogs do not write about: most semantic layer projects fail. Not the technology, the rollout. I have watched this play out enough times to see the same patterns.
Centralizing the chaos
If the business already disagrees about what revenue or active user means, a semantic layer does not resolve the disagreement. It just moves it to a more visible place. Five departments now fight over the centralized definition instead of the decentralized one, and the political cost of changing it is ten times higher. Reconcile the definitions with the business first. The semantic layer ratifies the agreement, it does not produce it.
Refactoring inside the semantic layer
Moving undocumented, ad-hoc BI calculations into a semantic tool just centralizes your technical debt. The layer becomes the new shrine of legacy mess, and nobody dares touch it for fear of breaking the dashboards on top. Clean up and standardize the underlying logic before you lift it. Otherwise the layer that was supposed to bring clarity inherits all of the old confusion in a more authoritative wrapper.
Reinventing dbt poorly
The moment you start expressing complex multi-step transformations in your semantic layer, you have put the wrong work in the wrong place. The semantic layer is for definitions and mapping, not compute. If a metric requires heavy logic, push that work into the data pipeline as a materialized table and let the semantic layer point at it. Mix the two and your semantic layer becomes a slow query engine, or your warehouse becomes a glossary.
None of these are sexy failures. They do not sell themselves the way "talk to your data" does. But they are the difference between a working agentic analytics system and an expensive demo.
The next phase won't be won by AI alone. It will be won by the teams who do the data discipline work that makes AI useful.
Near-term predictions
Here's where I think things are headed over the next 18 months.
1. The semantic layer becomes table stakes. The resurgence is already happening. By the end of 2026, having a semantic layer becomes the expected baseline, not a competitive edge. Companies still relying on tribal-knowledge metric definitions will start losing AI-tooling capabilities they thought they were buying.
2. Enterprise vendors race to ship conversational analytics. This is already underway. Snowflake Cortex, Omni Analytics, Cube's agentic features, Looker + Gemini, every major BI vendor is shipping a "talk to your data" interface within a year. The bottleneck won't be the AI. It will be whether the data underneath is actually queryable by an agent.
3. Semantic standards consolidate around OSI. The pressure toward a single open format is real. The alternative (a fragmented vendor-specific layer for every tool you use) is too painful. Expect more vendors to declare OSI compatibility, and expect MetricFlow's open-source positioning to pull more teams toward dbt as the de facto standard.
4. The AI-native data scientist becomes the standard hire. Job postings already reflect this. Employers expect candidates to scaffold work with AI tools rather than hand-write everything from scratch. The traditional workflow (days of manual research, hand-written boilerplate, tools used in isolation) is giving way to one where you wire AI tools together as a system and synthesize across approaches in hours.
Here's my recommendation to data scientists: be part of that design process.
You already understand how data connects to business value, which makes you uniquely positioned to shape this new layer of intelligence. Don't wait for vendors or AI teams to define it for you.
Experiment, build prototypes, and think about how context, governance, and reasoning can live inside the tools you already use.
What this means for data scientists
The work you've been doing, building models, uncovering insights, helping teams make better decisions, isn't going away. What's changing is the surface you do it on. Less time wrestling with column names and reverse-engineering metric definitions. More time on the actual analytical questions the business actually wants answered.
The combination of semantic layers, OSI, and agentic analytics points toward systems that understand business context and reason about data closer to how a thoughtful analyst would. That doesn't replace the analyst. It changes what being an analyst means.
If you've stuck with me to this point, take it as your signal to start experimenting now, not in eighteen months when this stack is table stakes. The data scientists who put hands on semantic layers and prototype agents in 2026 will be the ones defining how analytics gets done in the years that follow.
Frequently asked questions
What is a semantic layer in simple terms?
A semantic layer is a single, machine-readable place where your business metrics, dimensions, and relationships are defined, so every tool that touches your data (dashboards, notebooks, AI agents) interprets "active user" or "revenue" the same way. Think of it as the translator between raw tables and business meaning.
What is the difference between a semantic layer and a data catalog?
A data catalog is mostly a directory: it tells you what tables and columns exist, who owns them, and where they live. A semantic layer goes one step further. It defines what those columns mean in business terms, including metric calculations and the relationships between entities. Catalogs help you find data; semantic layers help tools (and AI agents) actually use it correctly.
Why does a semantic layer matter for AI agents specifically?
Because AI agents are only as good as the context they get. Without a semantic layer, an agent has to guess what "monthly active users" means, and different agents (or different prompts) will guess differently, leading to numbers that quietly contradict the dashboards your team already trusts. A semantic layer eliminates the guesswork.
What is the Open Semantic Interchange (OSI)?
OSI is an open standard, announced in September 2025, for how data and AI tools describe and share business context. It is backed by Snowflake, dbt Labs, Google, Cube, and others. The goal is to make metric definitions portable across vendors so the same definitions power your BI tools, your notebooks, and your AI agents.
Do I need a semantic layer to build an AI agent over my data?
Strictly, no. You can hardcode definitions in prompts or write SQL by hand. But the moment you have more than one agent, more than one prompt author, or definitions that need to change over time, the lack of a semantic layer becomes the reason your numbers stop matching across tools. For anything beyond a demo, a real semantic layer is what keeps the system trustworthy.
Is a semantic layer the same thing as an ontology?
Closely related but not identical. A semantic layer is usually scoped to a specific organization's data model: its tables, metrics, and relationships. An ontology is a more general framework for describing entities and how they relate, often used across organizations or domains. In practice, the lines blur in modern AI tooling, which is why both terms are showing up in the same conversations right now.